
问题背景
如果你想把你的模型投入到应用中或者是想提升模型的运行速度,除了对网络进行压缩、蒸馏外,最好的方法就是将模型转成tensor模型,使用tensorrt实现对网络的加速。但是当该模型的功能是图像增强或者是图像生成,并且模型中运用了大量的batchnorm2d函数,运用网上现成的方法会发现模型转成onnx以及trt后,模型的处理效果大幅下降,想解决此问题就可以详细往下看了:
我们的方法顺序是:pytorch模型先转成onnx模型,接着将onnx模型转成trt模型
一、pytorch to onnx
核心代码:
import torch
from torchvision.utils import save_image
import os
from nets.tiny_unet_2_channelxiangdeng_RCABup3_1_3 import Decoder
import argparse
import torch.nn as nn
from torchvision import transforms as T
from torchvision.datasets import ImageFolder
from torch.utils import data
import onnx
import onnxruntime
class Loader(nn.Module):
def __init__(self, image_dir, batch_size=1, num_workers=4):
super(Loader, self).__init__()
self.image_dir = image_dir
self.batch_size = batch_size
self.num_workers = num_workers
def forward(self):
transform = list()
transform.append(T.Resize([704, 1280])) # 注意要为256的倍数
transform.append(T.ToTensor())
transform.append(T.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)))
transform = T.Compose(transform)
dataset = ImageFolder(self.image_dir, transform)
data_loader = data.DataLoader(dataset=dataset,
batch_size=self.batch_size,
num_workers=self.num_workers)
return data_loader
class Solver(object):
def __init__(self, data_loader, config):
self.data_loader = data_loader
self.global_g_dim = config.global_G_ngf
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model_save_dir = config.model_save_dir
self.result_dir = config.result_dir
self.build_model()
def restore_model(self, resume_epoch):
"""Restore the trained generator and discriminator."""
print('Loading the trained models from step {}...'.format(resume_epoch))
generator_path = os.path.join(self.model_save_dir, '{}-global_G.ckpt'.format(resume_epoch))
self.generator.load_state_dict(torch.load(generator_path, map_location=lambda storage, loc: storage))
def build_model(self):
"""create a generator and a discrimin"""
self.generator = Decoder(self.global_g_dim)
self.generator.to(self.device)
def denorm(self, x):
out = (x + 1) / 2
return out.clamp_(0, 1)
def to_numpy(self, tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
def test(self):
begin_epoch = 91
end_epoch = 92
step = 1
for k in range(begin_epoch, end_epoch, step):
self.restore_model(94)
self.generator.train()
modelData = "../model/demo" + str(k) + ".onnx"
# modelData = "demo_distok-1ok" + str(k) + ".onnx"
data_loader = self.data_loader
# with torch.no_grad():
for i, (val_img, _) in enumerate(data_loader): # 出来的图片是RGB格式, 用PIL读取的
if i % 50 != 0:
continue
x_real_name = data_loader.batch_sampler.sampler.data_source.imgs[i][0]
basename = os.path.basename(x_real_name)
result_path = os.path.join(self.result_dir, str(k)) # 生成的图片的保存文件夹
if not os.path.exists(result_path):
os.makedirs(result_path)
result_path2 = os.path.join(result_path, basename)
distored_val = val_img.to(self.device)
clean_fake1 = self.generator(distored_val)
torch.cuda.synchronize()
clean_fake1 = clean_fake1.data.cpu()
save_image(self.denorm(clean_fake1), result_path2, nrow=1, padding=0)
torch.onnx.export(self.generator, distored_val, modelData, opset_version=9)
onnx_model = onnx.load(modelData)
onnx.checker.check_model(onnx_model)
ort_session = onnxruntime.InferenceSession(modelData,
providers=['CUDAExecutionProvider'])
ort_inputs = {ort_session.get_inputs()[0].name: self.to_numpy(distored_val)}
ort_outs = ort_session.run(None, ort_inputs)
result_path1 = os.path.join(self.result_dir, "trt"+str(k))
result_pathtrt = os.path.join(result_path1, basename)
#save_image((self.denorm(torch.tensor(ort_outs[0]))),result_pathtrt, nrow=1, padding=0)
result = [val_img, torch.tensor(ort_outs[0]), clean_fake1]
result_concat1 = torch.cat(result, dim=3)
# break
save_image((self.denorm(result_concat1.data.cpu())), result_path2, nrow=2, padding=0)
def main(config):
data_loader = Loader(config.data_dir)
solver = Solver(data_loader(), config)
solver.test()
#solver.build_model()
#solver.printnetwork()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--global_G_ngf', type=int, default=16, help='number of conv filters in the first layer of G')
parser.add_argument('--num_workers', type=int, default=4)
parser.add_argument('--data_dir', type=str,
default=r'D:\Data\Paired\underwater_imagenet\val')
parser.add_argument('--model_save_dir', type=str,
#default='/home/ouc/Li/Torch2TRT/trt_outfile/model'
default=r'C:\TensorRT-8.6.0.12\samples\python\zzzzFSpiral\modules')
parser.add_argument('--result_dir', type=str,
default=r'C:\TensorRT-8.6.0.12\samples\python\zzzzFSpiral\result')
torch.cuda.set_device(0)
config = parser.parse_args()
main(config)当pytorch转成onnx时,需要将模型进行eval模式,因为在PyTorch中,模型训练和推理(inference)有两种模式:训练模式和评估模式(evaluation mode)。在训练模式下,模型会保留一些中间结果,以便进行反向传播和参数更新(如batchnorm2d在train和eval模型中的计算不一致,涉及到内部的变量running_mean和running_eval的计算(如下图所示))。而在评估模式下,模型不会保留这些中间结果,以便进行推理。因此,在将PyTorch模型转换为ONNX模型时,需要将模型切换到评估模式,以确保模型的输出与推理结果一致。如果在转换模型之前不将模型切换到评估模式,可能会导致转换后的ONNX模型输出与预期不一致。因此,为了确保转换后的ONNX模型的正确性,需要将PyTorch模型切换到评估模式(eval mode)再进行转换。
class MyBatchNorm2d(nn.BatchNorm2d):
def __init__(self, num_features, eps=1e-5, momentum=0.1,
affine=True, track_running_stats=True):
super(MyBatchNorm2d, self).__init__(
num_features, eps, momentum, affine, track_running_stats)
def forward(self, input):
self._check_input_dim(input)
exponential_average_factor = 0.0
if self.training and self.track_running_stats:
if self.num_batches_tracked is not None:
self.num_batches_tracked += 1
if self.momentum is None: # use cumulative moving average
exponential_average_factor = 1.0 / float(self.num_batches_tracked)
else: # use exponential moving average
exponential_average_factor = self.momentum
# calculate running estimates
if self.training:
mean = input.mean([0, 2, 3])
# use biased var in train
var = input.var([0, 2, 3], unbiased=False)
n = input.numel() / input.size(1)
with torch.no_grad():
self.running_mean = exponential_average_factor * mean\
+ (1 - exponential_average_factor) * self.running_mean
# update running_var with unbiased var
self.running_var = exponential_average_factor * var * n / (n - 1)\
+ (1 - exponential_average_factor) * self.running_var
else:
mean = self.running_mean
var = self.running_var
input = (input - mean[None, :, None, None]) / (torch.sqrt(var[None, :, None, None] + self.eps))
if self.affine:
input = input * self.weight[None, :, None, None] + self.bias[None, :, None, None]
return input当模型是train时,其mean = input.mean([0, 2, 3]);var = input.var([0, 2, 3], unbiased=False),计算与当前的输入相挂钩,但是当模型是eval模式时,其mean = self.running_mean;var = self.running_var,计算与当前的输入无关,而是将学习到的running_mean与running_var直接作为当前计算的mean与var,由于该学习得到的均值与方差(running_mean与running_var)并不能完全适用所有的输入样例,因此模型在eval模式下的处理效果极大降低。
但是有人可能会想为什么模型转成onnx时要将模型设置为eval模式,直接设置为train模式不就可以解决处理效果下降的问题了吗?但是当你按该想法实验的时候,会发现虽然pytorch模型的处理效果没问题,但是onnx模型的处理效果还是一样的差,这又是为什么呢?我的猜测是onnx模型在推理时默认将batchnorm的模式设置为eval,进而输出的结果就存在问题了。这个是我个人的想法,大家有不同意见可以互相交流。
所以现在的问题就转换到了如何使模型在eval模式下计算的mean与var和当前输入相关,而不是依赖学习到的running_mean与running_eval。部分人可能遇到此问题就无从下手了,认为该问题是无法解决的。但是这个问题在我这里是能解决的。首先经过上述对问题的描述,大家对这个问题已经是比较清楚了。
接下来我将介绍两种很简单的方法来解决onnx模型处理效果差的问题:
方法一:
具体措施:
修改batchnorm2d中的源码,在if self.training:上方加一行self.training =True。这样尽管处于eval模式,但是batchnorm仍然是处于训练状态的,在这种情况下,mean与var自然就和input挂钩了。
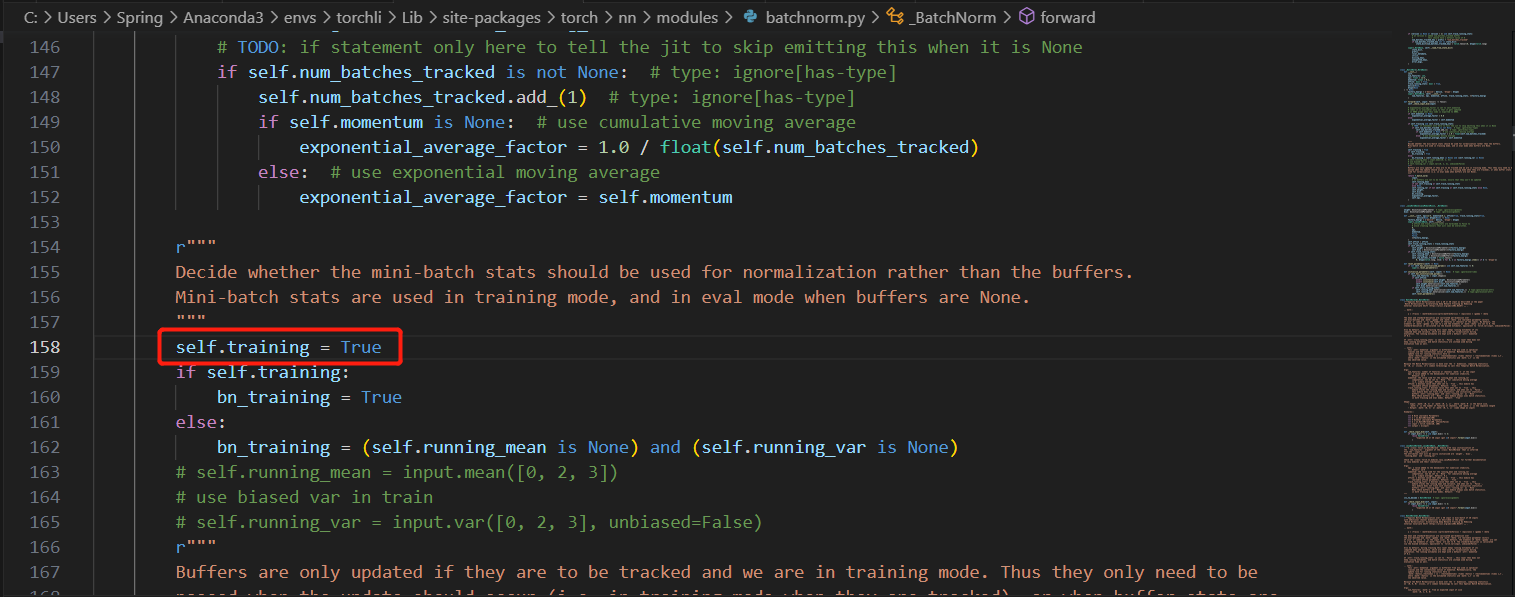
利弊:
不过这种方法虽然可以解决onnx模型处理效果差的问题,但是由该方法获得的onnx模型是无法成功转tensorrt的。原因是因为onnx模型的参数都是固定死的,正如上述我所展示的代码中,当模型处于训练模式时,running_mean与running_var是变化的,因此获得的onnx尽管输出没问题,但其内部是存在问题的。
batchnorm2d的源代码路径如下:
C:\Users\Spring\Anaconda3\envs\torchli\Lib\site-packages\torch\nn\modules\batchnorm.py
方法二
具体措施:
修改batchnorm2d的源码,不过与方法一有所区别,具体修改见下图,之所以这样修改是因为batchnorm在eval模式下,mean与var和running_mean与running_val挂钩,故我们提前将学习到的running_mean与running_var设置成与input挂钩,然后就mean与var就和input联系起来了。
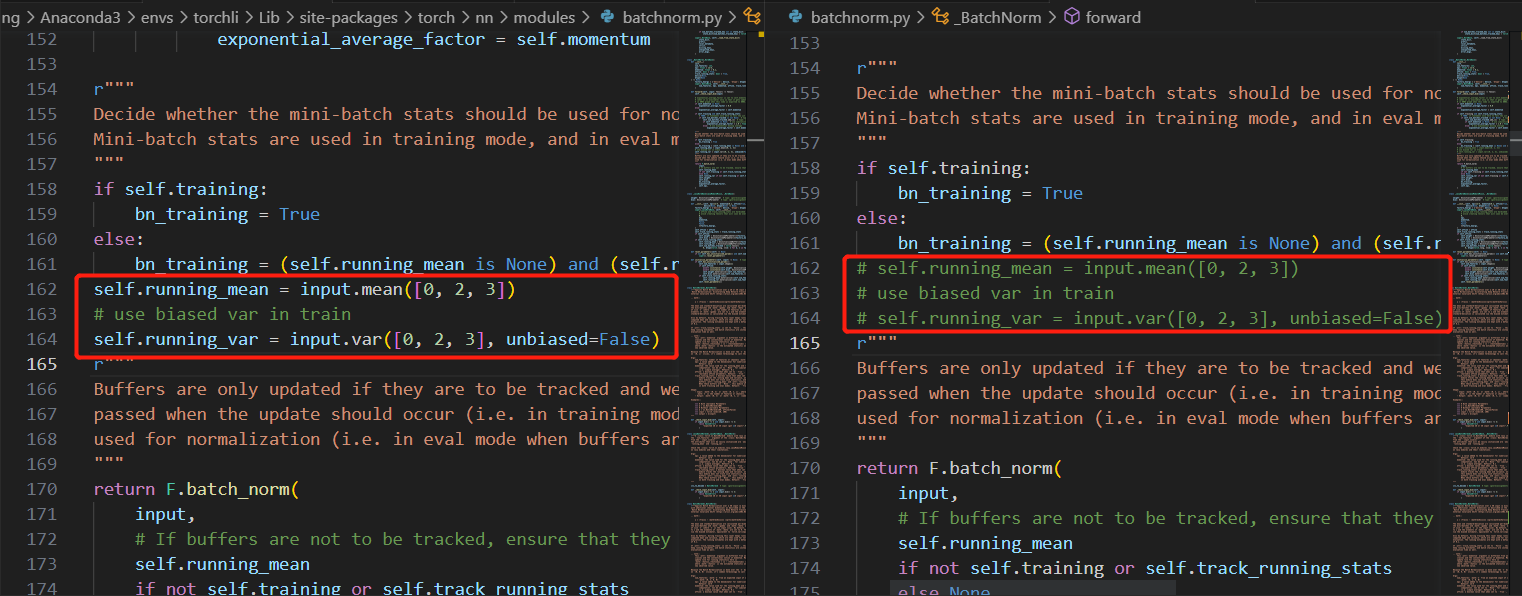
利弊:
不过这种方法虽然可以解决onnx模型处理效果差的问题,但是当可视化由该方法获得的onnx模型时,会发现batchnorm是不纯净的,上方多了一些计算分支(如右图所示),但是方法一的batchnorm是纯净的(如左图所示)。好处是由该方法获得的onnx模型是可以顺利转成trt模型的。
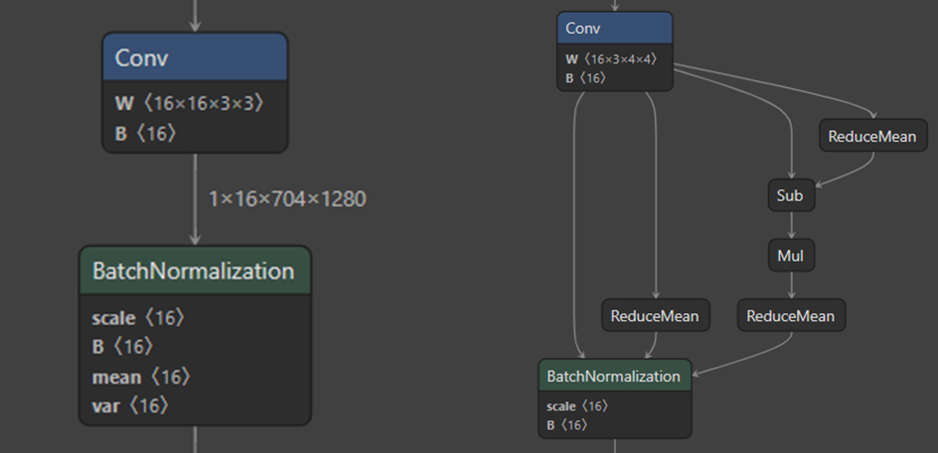
二、onnx to trt
终端转换命令:
Windows
.\trtexec.exe --onnx=aaa.onnx --saveEngine=retinate_hat_hair_beard_sim.trt --device=0
Ubuntu
trtexec --onnx=aaa.onnx --saveEngine=retinate_hat_hair_beard_sim.trt --device=0
使用trt模型进行推理:
import torch
from torch.autograd import Variable
import tensorrt as trt
import pycuda.driver as cuda
from torchvision.utils import save_image
import os
import pycuda.gpuarray as gpuarray
import pycuda.autoinit
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision import transforms as T
from torchvision.datasets import ImageFolder
import time
import numpy as np
from torch.utils import data
import torch.nn as nn
import time
# 操作缓存,进行运算, 这个函数是通用的
def infer(context, input_img, output_size, batch_size=1):
# Convert input data to Float32,这个类型要转换,不严会有好多报错
input_img = input_img.astype(np.float32)
# Create output array to receive data
output = np.empty(output_size, dtype=np.float32)
# output = np.empty(batch_size * output.nbytes)
# Allocate device memory
d_input = cuda.mem_alloc(batch_size * input_img.nbytes)
d_output = cuda.mem_alloc(batch_size * output.nbytes)
bindings = [int(d_input), int(d_output)]
stream = cuda.Stream()
# Transfer input data to device
cuda.memcpy_htod_async(d_input, input_img, stream)
# Execute model
context.execute_async(batch_size, bindings, stream.handle, None)
# Transfer predictions back
cuda.memcpy_dtoh_async(output, d_output, stream)
stream.synchronize()
# Return predictions
return output
class Loader(nn.Module):
def __init__(self, image_dir, batch_size=1, num_workers=4):
super(Loader, self).__init__()
self.image_dir = image_dir
self.batch_size = batch_size
self.num_workers = num_workers
def forward(self):
transform = list()
transform.append(T.Resize([704, 1280])) # 注意要为256的倍数
transform.append(T.ToTensor())
transform.append(T.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)))
transform = T.Compose(transform)
dataset = ImageFolder(self.image_dir, transform)
data_loader = data.DataLoader(dataset=dataset,
batch_size=self.batch_size,
num_workers=self.num_workers)
return data_loader
def denorm(x):
out = (x + 1) / 2
return out.clamp_(0, 1)
# 执行测试函数
def do_test(context, batch_size=1):
# train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = Loader(image_dir='/home/ouc/LiModel/data-paired/underwater_imagenet/val/')
print("mnist data load successful!!!")
accurary = 0
start_time = time.time()
times = []
for i, (val_img, _) in enumerate(test_loader()): # 开始测试
# img, label = data
x_real_name = test_loader().batch_sampler.sampler.data_source.imgs[i][0]
basename = os.path.basename(x_real_name)
img = val_img.numpy() # 这个数据要从torch.Tensor转换成numpy格式的
# print(img)
# label = Variable(label, volatile=True)
# with torch.no_grad():
# label = Variable(label)
start_time1 = time.time()
output = infer(context, img, img.shape, 1)
end_time1 = time.time()
print(end_time1 - start_time1)
times.append((end_time1 - start_time1))
result_trt = torch.tensor(output)
# print(result_trt.shape)
# print(val_img.shape)
result = [val_img, result_trt]
result_concat1 = torch.cat(result, dim=3)
save_image((denorm(result_concat1.data.cpu())), '/home/ouc/Desktop/python/zzzzFSpiral/result/trt/' + basename, nrow=2, padding=0)
#print(output)
# conf, pred = torch.max(torch.Tensor(output), -1)
# num_count = (pred == label).sum()
# accurary += num_count.data
end_time = time.time()
print((start_time - end_time)/len(test_loader()))
print(np.mean(times))
# print("Test Acc is {:.6f}".format(accurary / len(test_dataset())))
# return accurary/len(test_dataset), time.time() - start_time
def trt_infer():
# 读取.trt文件
def loadEngine2TensorRT(filepath):
G_LOGGER = trt.Logger(trt.Logger.WARNING)
# 反序列化引擎
with open(filepath, "rb") as f, trt.Runtime(G_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
return engine
trt_model_name = "./resnet3.trt"
engine = loadEngine2TensorRT(trt_model_name)
# 创建上下文
context = engine.create_execution_context()
print("Start TensorRT Test...")
do_test(context)
# print('INT8 acc: {}, need time: {}'.format(acc, times))
if __name__ == '__main__':
trt_infer()